October 20, 2021
ken-oestreich
Earlier this month, ZDNet reported that Python is challenging C and Java to become the most popular programming language. We’d like to see that happen. But maybe not why you think.
Unlike languages like C that have direct access to hardware, Python (as a “high-level language”) is slow because it’s an interpreted language. Hence the “popularity-vs-performance” issue: Python is simple to use, but due to layers of abstraction, it’s not terribly high-speed. Nor does it inherently have scale-out power, e.g. parallelization for compute-intensive Data Engineering… e.g. ETL, or AI/ML work.
That’s about to change.
At Bodo, we exist to change the face of analytics computing; to democratize access to performance, scale, and simplicity for data-intensive applications.
We asked, what if Python was compiled? What if it had full type checking? And, what if it could execute in a true MPI-style parallel architecture using generated native machine code?
Well, the result would achieve the performance of machine code like C or Scala. And it would have massive scaling linearity. It would also mean a giant leap forward in Python’s value to people like Data engineers and AI/ML engineers doing things like ETL, benefiting from a more accessible -- AND more powerful -- engine to speed their work.
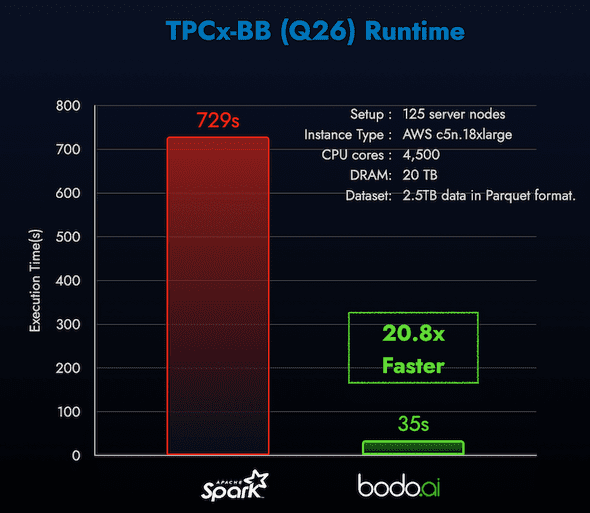
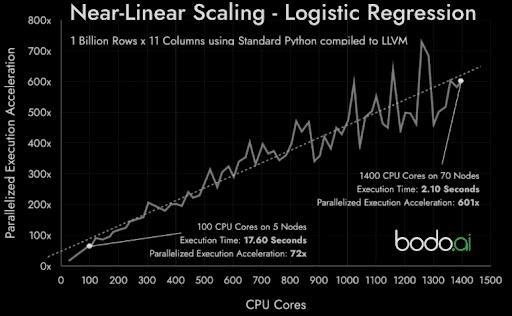
Now, there are libraries (like Spark, Dask and Ray) that attempt to approximate parallel computing. But they’re fundamentally limited since they use a “Driver-Executor” approach. That is, every little parallel task has to be continuously scheduled. Arguably, the other limitations on these approaches are that they’re not transparent to the programmer - they require new APIs and commands to learn, and new techniques to master.
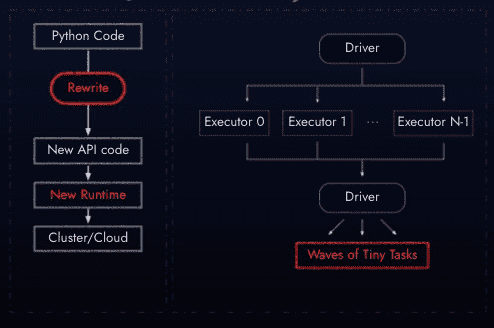
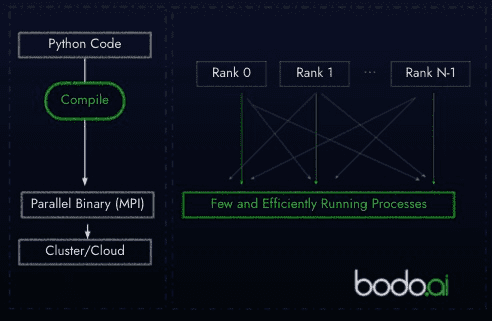
Instead, the Bodo model compiles native code, using an inferential approach looking at code structure and semantics - and then generates new machine code optimized for MPI parallelization. No new APIs, no new libraries, no re-coding into C or Scala.
Plus, computing resources are used extremely efficiently with this model, since there is no wait-state time, idling around for a scheduler to assign a new task. So not only is the compilation method speedier, but it makes a far more efficient approach to infrastructure. Oh…. and you can make your clusters scale-up or down without any change to code whatsoever.
According to Stack Overflow, Python is now the most searched-for term for Data Scientists. That’s because they’re looking for an accessible approach to prototyping work.
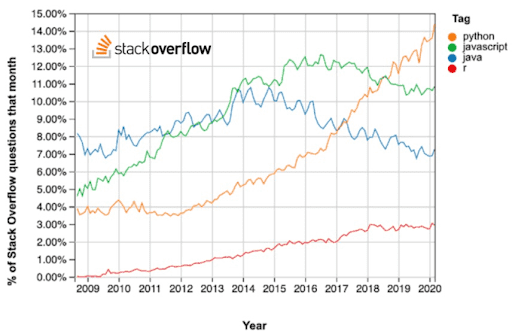
But what if their Python prototypes could easily scale into full production? Better yet, what if their Data Engineer colleagues, constantly working with massive ETL ingestion jobs, could find a simpler (read: Python-based) approach, that was also faster and more resource-efficient?
That’s what we’re out to enable and to change.
This parallelization approach has long been a “holy grail” for researchers working on solving the gap between simplicity and performance in computing.
By democratizing access to parallel computing, we aim to accelerate data insights in ways the industry can’t yet imagine. And by doing so, we might just help Python attain the #1 position, too.




